Artificial Intelligence and the PGF: (Deep)Mind the Gaps
Artificial Intelligence and Deep Learning has become all the rage over the last decade, especially with the publication of AlexNet in 2012 combined with the rising power of parallel computing via graphics cards (GPUs). AlexNet was the seminal work spurring the rise of deep CNNs (Convolutional Neural Nets, not Anderson Cooper) that are now popping up in consumer technologies everywhere, from social media image filters to your smart phone (unless you’re Derek Randles).
For all their magic and industry buzzword frenzy, a deep CNN is fundamentally just a giant math equation stitched together that take images as input and spit out something important. To get a layman’s understanding of how this works, you just need to have a conceptual grasp of two components: Photoshop filters, and recursive multivariable vector calculus.
A photoshop filter basically works like this: Given an image, which to a computer is just a grid of numbers representing color values on a scale from 0 to 255, produce a new image whose pixels are a blended combination of the original pixel and its neighbors. The filter size and the blend weights at each pixel make up the kernel. An example 3×3 kernel operating on a pixel would look like the example below.
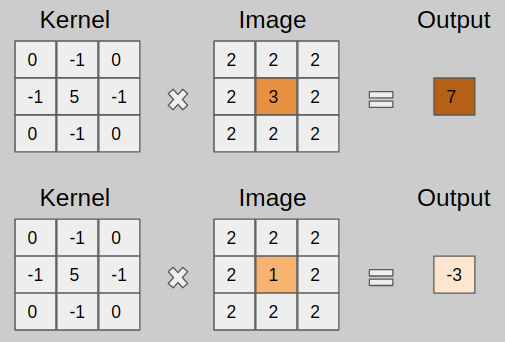
This process, applied to every pixel in the input image, is called convolution. There are many different kernels that produce different effects. Whenever you apply a filter in Photoshop, some version of this operation is happening. An example is the Sobel filter, which emphasizes the edges of an image and blacks out everything else.


A deep CNN stacks a whole bunch of these end on end, filtering the outputs of previous filters. As a diagram, it would look something like this:

Why is this useful? It turns out if you screw with the weights in the kernels in the right way and combine enough of these convolutions together, you can go from blurring or sharpening your vacation photos to detecting cancer in histologies or teaching cars to drive themselves. It is how computers “learn” to play complex strategic games such as chess or go, as demonstrated when Google’s DeepMind AI beat the world champion in 2017. The mathematical methods behind how these kernels are determined is where the vector calculus comes in, and before you all break into a cold sweat, I’m going to skip the details on breaking down backpropagation of vector gradients because it would take way too long.
The conceptual idea behind how all deep learning networks work is pretty similar to how people and animals learn: You input an image of a cat, the network takes a guess based on all the numbers in all of its kernels and guesses that you showed it a pig. You input the correct answer as cat, and the network adjusts the values in its filters to make its answer closer to “cat” for the observed image. You do this thousands of times, with many different images of cats, and eventually the filters “learn” how to recognize a cat.
Why is this exciting to us? Some universities and industry research labs trained deep CNNs to upscale old film, which conveniently lends itself to making the 50 year old PGF look really pretty. It would have gone something like this: You have a deep-CNN with some random numbers scrambled in the middle. You take hundreds, maybe thousands of hours of 4k, 60FPS footage (many terabytes of data) and you 1)downsample the image to say, 720p and 2) scramble it somehow with some random noise + blurs. You show the network the screwed up frames, and you ask it to guess what the clean 4K version is. It takes its best shot, then compares it to the original ground truth frames, takes the differences, and adjusts.
You then take another separate network, chop out half the frames of the 4K film such that you only see every other frame at 30fps, and give it two successive frames. The objective is to output the missing frame in the middle. It takes its best guess, and then you show it the actual missing frame you removed. It takes the differences, and adjusts.
If you throw enough training data at these networks, you now have two networks that can 1) take a poor resolution image and expand it to 4K by making up a bunch of pixels based on the filters it learned and 2) given two frames, make up an entirely new frame that would interpolate them. The equations adapted their values to best predict the upscaled film on frames for which the real answer exists (the training data) and attempts to then predict the correct answers on unseen frames for which there is no known answer (the test data).
If you throw the PGF at networks such as these, you can get some pretty neat looking results. But I didn’t rant on about a crash course in deep learning and convolutional neural nets just because I was bored. You need to understand something very important when you look at these videos, and any videos or images like this that may come out in the future, i.e. if someone films a suspected “sasquatch” and throws it at some fancy new enhancement technology on their smartphone before posting it on YouTube.
A deep-CNN upscales, or interpolates frames, by essentially hallucinating the missing data based on the filters it optimized by processing terabytes of training data. It’s essentially taking an educated guess at what should be there and makes it up like movie magic. This looks all well and good for TV, but you CANNOT and most definitely SHOULD NOT take material like this and study it frame by frame, treating details like actual data. This would be like a paleontologist watching Jurassic Park to study the biomechanics and physiology of T. Rex. I don’t want to see any of you drawing red circles on frames from these videos or any “AI UPSCALED BIGFOOT EVIDENCE!!!” or MK Davis posting a frame by frame breakdown of one of these on his channel, because what you’re looking at by and large was generated by a math equation. You may find weird artifacts like disconnected limbs, extra fingers, or random blobs appearing out of thin air, and all of these are the side effects of asking a glorified Photoshop filter to do a forensic sketch with limited data and not at all evidence that what you’re seeing is some kind of interdimensional shapeshifter.
That being said, these videos are quite good at making it easier on your eyes to understand what they’re seeing by filling in a lot of the blanks for your brain, especially when it comes to motion. Played at full speed it’s pretty hard to notice the many defects that exist at the pixel level. Please enjoy responsibly.

{kind=link}
{kind=link}
{kind=link}
{kind=link}